深度學習筆記
AI>ML>DL
AI:
- Neural Network→DL的祖先
- Fuzzy Theory:有程度的變數
- Genetic Algorithm:由Evolution(演化) Algorithm而來
量子電腦Quantum Computer:縮小AI體積、加快運算速度
ML學習法:
- 監督Supervised learning(最常用):分類、迴歸
- 非監督Unsupervised learning:聚類
- 半監督Semi-Supervised learning:少量資料已label
- 增強Reinforcement learning:獎賞機制、評估(有交互作用、需有高階設備),用於分類
- 轉移Transfer learning:轉移某個已經學好的參數到一個新的模型上使用,用於資料集較少的。
BPNN,1985年,是multilayer perceptron架構(全連接)+Backpropagation Learning Algorithm(為監督式),可用於非線性分類處理。傳統BP一個神經元只能分2類。
傳統NN/DL:
- DNN深度學習(Deep Neural Networks):多層NN
- 全連結Fully Conected
- 有很多權重值/參數要訓練
- 就是有很多隱藏層的BPNN
- CNN捲積(Convolutional Neural Networks):抽特徵
- Convolution捲積:neighborhood processing特徵抽取,公式:R=g*f=ΣΣg(i,j)*f(x+i,y+j),g:filter、f:原始訊號。
- 包含Convolution層(feature Extraction)、[Pooling](feature Selection)、Fully connected層(Classification),前兩層目的在於降維。
- 例如:LeNet5、AlexNet、GoogleNet......
- AlexNet:5個捲積產生feature map,每個捲積層之後都有一個ReLu非線性啟動層完成非線性轉換。3個池化有max pooling和Average pooling降低特徵圖的解析度。3個全連接,最後有softmax歸一化指數層(分類機率)。
- RNN(Recurrent Neural Network):回饋
- 後面的節點會倒傳遞到前面或自己
- 常用於NLP(自然語言)ex:LSTM
- 文本處理、語言辨識、輿情分析(ptt、IG)
- GAN生成對抗網路(Generative Adversarial Network):資料擴增、模仿
- 是由Generator網路(生成器)和Discriminator(鑑別器)所組成
- 生成器生成假的(仿真)data,要騙過鑑別器
傳統AI的做法:DFS(Deep First Search)深度優先、BFS(Breadth First Search)廣度優先
Kaggle:線上社群、比較ML模型的性能、有資料集、提供Python/R語言環境、徵才訊息
評估可不可以使用AI(Deep Learning Solution):
- Dataset資料集
- Model模型:如ResNET、BERT(文字文章)
- Framework框架:如Keras、TensorFlow、PyTorch目前最流行(開發)、Cuda-C達到real-time(應用)
- Hardware硬體:第一優先考量,與成本有關(GPU、CPU、TPU、記憶體)
DICOM:為一通訊標準,目前版本為DICOM 3.0
- 一般
- 核醫用:DICOM RT(Radio Therapy)(放射設備數據傳輸標準)→有顏色
TinyML:將AI放到MCU(微處理器Micro Computer/微控制器Controller Unit:計算能力較低、記憶體較小,如嵌入式系統Embedded System、行動裝置),快速發展ML、低功耗(mV以下)、Always On,ARM架構(Advanced RISC Machine)精簡指令集。
ARM公司:CPU處理技術ARM,開發嵌入式系統。
CISC:複雜指令集,指令多、長度不固定,PC、Server
RISC:精簡指定集
Edge Impluse:線上訓練model
perceptrons感知器:第一代神經網路,前饋(Feedforward)神經網路,是一種二元線性分類器。
Hyperparameters超參數:需人工手動設定的數值(2020後也可透過訓練獲得)ex:Learning rate,設定在[0,1]區間,通常設0.5,1太快0太慢。
backpropagation學習演算法:倒傳遞error(期望值-實際值),更新權重。
深度學習之演算法:在有限時間、步驟下,解決問題的方法。表示方法(Pseudocode虛擬碼)可用類程式敘述或文字+數學。
- Training/Learning Algorithm:由損失函數和最佳化方法組成。
- Prediction/Testing Algorithm→真正上線用的
損失函數:error/cost/lost function,用來計算實際輸出和理想輸出之間的關係(差值、entropy)。
最佳化Optimization:在一個有許多限制、條件相互衝突的環境下,找到最合適的解決方法。ex:梯度下降法(Gradient descent, GD)找到損失函數的局部極小值(誤差最小)。另還有SGD、min-batch SGD、Adagrad、Adam......
訓練/學習演算法步驟:
- 參數、超參數初始化(跟transfer learning有關)
- forward計算出實際輸出。(先了解有那些數學運算式、Activation function)
- weight training/Backward計算,調整網路中的參數,用到的數學最多(損失函數、最佳化)
- interation:重複步驟2、3,直到滿足條件ex:參數沒有巨大變動。
NN需先決定:
- 架構:前向?回饋?
- 學習演算法:監督、非監督、半監督、聯想(Associate)、最適化(Optimization Application Network)?
資料結構/離散數學:圖論graph(點、邊edge)
- 無向圖
- 有向圖ex:NN
啟動函數Activation function(門檻值)ex:RELU、Sigmoid。
- 定義:是在NN的神經元上執行的函數,負責將神經元的輸入對映到輸出端。
- 特性:非線性、可微性、單調性、f'(x)≈x、輸出值的範圍(搭配learning rate)
- 使模型了解複雜、非線性函數。
- 模擬複雜型態的資料ex:影像、視訊、語音。
- 讓資料能夠更進一步地被分類。
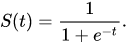







- model=sequential()建立一個空的架構框。
- model.add()建立架構(input、hidden、output layer)
- model.Dense()全連接
- model.complie()設定損失函數、最佳化方法
- model.fit()執行model的training、testing。
- model.fit_generator()、fit_batch()依據訓練資料設定Epoch(每個資料重複出現次數)、batch_size(幾筆資料分一堆,跟電腦的硬體等級有關)
threshold value(level)=bias
框架比較:

data太少會產生overfitting(過擬)→解決辦法:Batch Normalization
- 可以加速training、提升準確率。
- 可以對抗Overfitting。
- 防止 gradient vanishing (梯度消失)→或將Activation函數換成Relu。
- 可以幫助activation function,如:sigmoid、tanh。
- 可以讓參數的 initialization(初始化)的影響較小。